平均值,中值和模式是中央倾向的最常见测量,用于描述分布的中心。在三个中,平均值是最常用的,但中位数和模式也广泛使用。
![]() 我们需要区分
样本
平均值,中位数和模式,以及他们的
人口
同行。
我们需要区分
样本
平均值,中位数和模式,以及他们的
人口
同行。
![]() 通常,我们是
提供样品
我们需要计算样本意味着,样品中值和样本模式。这些统计数据是
估算器
相应的人口参数。
通常,我们是
提供样品
我们需要计算样本意味着,样品中值和样本模式。这些统计数据是
估算器
相应的人口参数。
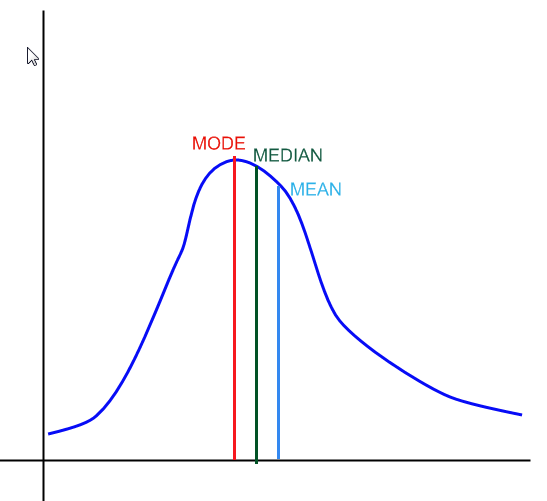
在上面的图表中,您有一个例子是中位数,模式和均值如何看待分发。
![]() 该模式对应于样本中最重复的值。在分布中,它对应于密度函数中的最高点,如上图所示。
该模式对应于样本中最重复的值。在分布中,它对应于密度函数中的最高点,如上图所示。
![]() 中位数大致,定义了50%的分布左侧的点,以及它的右侧。
中位数大致,定义了50%的分布左侧的点,以及它的右侧。
![]() 平均值对应于变量所带来的值的加权平均值及其相关概率(\(\sum x \cdot p(x)\))。对于分发,这种加权总和是一个总和或积分。对于样本,我们只需计算样本中的值的平均值。
平均值对应于变量所带来的值的加权平均值及其相关概率(\(\sum x \cdot p(x)\))。对于分发,这种加权总和是一个总和或积分。对于样本,我们只需计算样本中的值的平均值。
如何计算给定示例的平均值,中位数和模式
现在,假设我们给出了一个样本\(X_1, X_2, ..., X_n\),我们希望计算模式,中位数和均值。我们如何去做呢?
• 对于模式: 简单的。我们发现最重复的数字。例如:如果我们有一个样品1,2,2,2,3,1,4,模式为2,因为2是最重复的值(它重复3次)
• 为中位数: 此计算稍微涉及。拍摄样本\(X_1, X_2, ..., X_n\),第一步是按升序重新组织它。因此,假设\(\hat X_1, \hat X_2, ..., \hat X_n\)在重新排序到最高值之后是样本。
现在,我们将按升序计算样本中位数的位置。对于样本大小\(n\),我们计算\(P = 0.5 (n+1)\)。
![]() 如果此值是一个整数,那么我们发现中位数是p中的值
钍
按升序在样本中的位置。
如果此值是一个整数,那么我们发现中位数是p中的值
钍
按升序在样本中的位置。
![]() 如果此值不是整数,那么我们发现\(P_L\)和\(P_U\),它是\(P\)的左侧和右侧的最接近的整数。(例如:如果\(P = 10.2\),那么\(P_L = 10\)和\(P_U = 11\))。
如果此值不是整数,那么我们发现\(P_L\)和\(P_U\),它是\(P\)的左侧和右侧的最接近的整数。(例如:如果\(P = 10.2\),那么\(P_L = 10\)和\(P_U = 11\))。
然后,中间数是\(P_L\)的平移 钍 和\(P_U\) 钍 按升序在本地。
• 对于平衡: 简单。制品平均通道练用公共来牌
\[\displaystyle \frac{1}{n}\sum_{i=1}^n X_i\]例1
-
28,36,43,30,15,182,29,36,36,33,38,30,30,39,33,38,30,41,42,46,40,33,30,40,43,40,337,40,30,30,35,3.40,30,30,35,39,37,42,42,37,38,3.2,51
回答:
下载显示计算平衡所需的所需计算
|
数码 |
|
|
28。 |
|
|
36。 |
|
|
43。 |
|
|
30。 |
|
|
15。 |
|
|
19。 |
|
|
46。 |
|
|
36。 |
|
|
34。 |
|
|
38。 |
|
|
42。 |
|
|
29。 |
|
|
37。 |
|
|
35 |
|
|
39。 |
|
|
39。 |
|
|
30。 |
|
|
39。 |
|
|
36。 |
|
|
38。 |
|
|
30。 |
|
|
41。 |
|
|
42。 |
|
|
46。 |
|
|
40 |
|
|
33。 |
|
|
30。 |
|
|
40 |
|
|
43。 |
|
|
12. |
|
|
42。 |
|
|
39。 |
|
|
30。 |
|
|
35 |
|
|
38。 |
|
|
41。 |
|
|
30。 |
|
|
37。 |
|
|
40 |
|
|
30。 |
|
|
30。 |
|
|
35 |
|
|
39。 |
|
|
37。 |
|
|
42。 |
|
|
42。 |
|
|
37。 |
|
|
38。 |
|
|
32。 |
|
|
51。 |
|
|
总和= |
1791年。 |
|
平坦= |
35.82 |
因此,样本意味着
\[\bar{X}=\frac{1}{n}\sum{{{X}_{i}}}=\frac{1791}{50}=35.82\]现出,对于下载的中间数,按升序显示数据:
|
数量(按升序) |
|
12. |
|
15。 |
|
19。 |
|
28。 |
|
29。 |
|
30。 |
|
30。 |
|
30。 |
|
30。 |
|
30。 |
|
30。 |
|
30。 |
|
30。 |
|
32。 |
|
33。 |
|
34。 |
|
35 |
|
35 |
|
35 |
|
36。 |
|
36。 |
|
36。 |
|
37。 |
|
37。 |
|
37。 |
|
37。 |
|
38。 |
|
38。 |
|
38。 |
|
38。 |
|
39。 |
|
39。 |
|
39。 |
|
39。 |
|
39。 |
|
40 |
|
40 |
|
40 |
|
41。 |
|
41。 |
|
42。 |
|
42。 |
|
42。 |
|
42。 |
|
42。 |
|
43。 |
|
43。 |
|
46。 |
|
46。 |
|
51。 |
在这这情况下,中间的位置是p = 0.5 *(50 + 1)= 25.5,因此\({{P}_{L}}=25\)和\({{P}_{U}}=26\)。第25位的值 钍 在按升序中的数码中为37,并且第26次的值也是37.然后是中间数
\[Median=\frac{{37}+{37}}{2}=37\]是最重复值的,是30。
什么是大大的,平静的,中间数量或模式?
这是一个个经常弹出的。一切而而,没有分布都没有一个。这是,答案取决于分布。
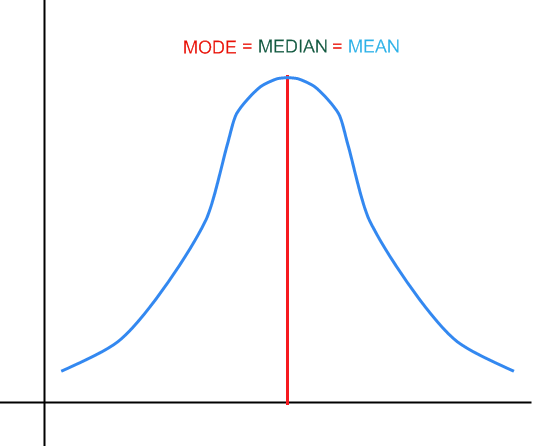
![]() 对于我们的对称分布
:
对于我们的对称分布
:
图片方:
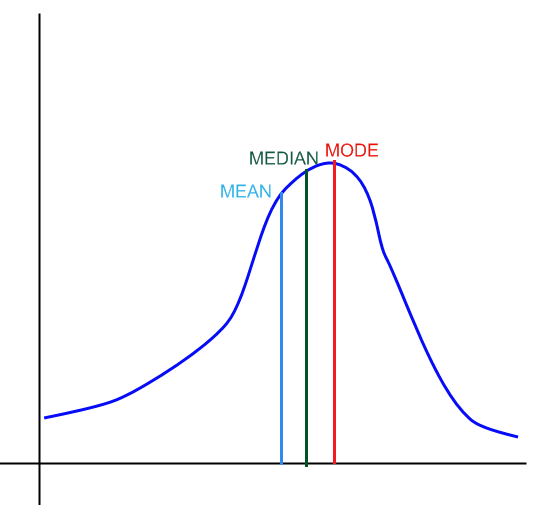
![]() 对于我们没有的分布
:
对于我们没有的分布
:
图片方:
![]() 对于我们没有的分布
:
对于我们没有的分布
:
图片方:
更多关键词平均值,中学数和模式
中间数,均值和模式是广泛,这些概念在统计中间使用。
根据销量水平,我们将使用不足的中心量。
•对于对于数码,我们签署该该。
•对于读数,我们签用该以及中心的量词。
•对于读数,我们实用中间数量或平衡为中心的量词。
•对于间距和比率数据,我们实用平衡(或中间数量如果分布太偏斜)作为中心的量。
使用程序
平坦,中间和模式是最均值和中间用词数码,该该用于分类数据。
对于销量数码,通务会使用平衡。有一个个警告:平等对异常值非常。
在这种情况下,当有异常值或分类相当倾斜时,优选使用中间数量作者
其中一代例子是收集收集品以评估受访者的。如果我们采取100人的样本,我们发表其中99人每年10,000美酒,每年1人赚1亿美容,该样本的平等收入将是(10,000 *99 + 1 * 100,000,000)/ 100 = $ 1,009,900.00。因此,平台而言,每个人都赚了1,009,900.00美酒,所以你会得到这个样本网子来自一个非常富裕的地址,但这并非如此:高度扭曲的平等。实际上,在这种情况下,中间数是10,000美酒,这是该样本的一个为之。
关联器
如果您需要查看逐步解决解决案,以计算中间趋势的平衡和其他措施,请退房 描述性描述性性器具 。你可以也可找到很有用的 5号仪器 。








如果您有任何建议,或者您想报告一个的求器/计算仪,请不要犹豫 联系我们 。