T-тест для среднего значения одной популяции
Инструкции: Данный калькулятор проводит t-тест для одного среднего значения популяции (\(\sigma\)) с неизвестным стандартным отклонением популяции (\(\sigma\)), поэтому вместо него используется стандартное отклонение выборки (s). Пожалуйста, выберите нулевую и альтернативную гипотезы, введите гипотетическое среднее, уровень значимости, выборочное среднее, выборочное стандартное отклонение и размер выборки, и результаты t-теста будут выведены на экран:
Как использовать данный калькулятор t-теста для одной выборки
Подробнее о Т-тест для одного среднего значения чтобы вы могли лучше интерпретировать результаты, полученные этим решателем: T-тест для одного среднего - это тест на гипотезу, который пытается сделать утверждение о среднем значении популяции (\(\sigma\)). Этот t-тест, в отличие от z-теста, не требует знания стандартного отклонения популяции \(\sigma\).

Как провести t-тест для среднего значения одной популяции?
Тест имеет две взаимодополняющие гипотезы - нулевую и альтернативную. Нулевая гипотеза - это утверждение о среднем значении популяции в предположении отсутствия эффекта, а альтернативная гипотеза - это дополнительная гипотеза к нулевой гипотезе. Основными свойствами одновыборочного t-теста для одного среднего популяционного значения являются:
- Для t-теста для одного среднего распределение выборки, используемое для статистики t-теста (которая является распределением статистики теста в предположении, что нулевая гипотеза верна), соответствует t-распределению с n-1 степенями свободы (вместо стандартного нормального распределения, как в случае z-теста для одного среднего)
- В зависимости от наших знаний о ситуации "нет эффекта", t-тест может быть двуххвостым, левохвостым или правохвостым
- Основной принцип проверки гипотез заключается в том, что нулевая гипотеза отвергается, если полученная тестовая статистика достаточно маловероятна при предположении, что нулевая гипотеза верна
- P-значение - это вероятность получения результатов выборки, таких же экстремальных или более экстремальных, чем полученные результаты выборки, при предположении, что нулевая гипотеза верна
- При проверке гипотез существует два типа ошибок. Ошибка типа I возникает, когда мы отвергаем истинную нулевую гипотезу, а ошибка типа II возникает, когда мы не можем отвергнуть ложную нулевую гипотезу
Как вычислить t-статистику для одной выборки?
Итак, какова формула одновыборочного t-теста? В данном случае формула t-теста для t-статистики имеет вид
\[t = \frac{\bar X - \mu_0}{s/\sqrt{n}}\]Нулевая гипотеза отвергается, если t-статистика лежит в области отклонения, которая определяется уровнем значимости (\(\alpha\)), типом хвоста (двуххвостый, левохвостый или правохвостый) и число степеней свободы \(df = n - 1\)

Что происходит с t-тестом, когда у меня 2 выборки
Обратите внимание, что это калькулятор t-теста для одной выборки. Если вместо этого вам нужно сравнить два средних значения, вам следует использовать t-тест для независимых выборок , вместо этого.
Аналогичным образом, у вас может быть две выборки, но они парные, совпадающие или повторяющиеся, и в этом случае следует использовать следующий инструмент калькулятор парных t-тестов , когда это так.
Решение для одновыборочного t-теста
Как принять решение по одновыборочному t-тесту? Во-первых, вам нужно знать t-статистику, которую мы называем \(t_{obs}\), и степени свободы df, чтобы вы могли вычислить p-значение.
Процесс расчета p-значения будет зависеть от типа определенных хвостов. Для теста с двумя хвостами p-значение вычисляется как \(p = \Pr(|t_{df}| > |t_{obs}|)\). Затем, для теста с левым хвостом, p-значение вычисляется как \(p = \Pr(t_{df} < t_{obs})\), а для теста с правым хвостом, p-значение вычисляется как \(p = \Pr(t_{df} > t_{obs})\).
Пример одновыборочного t-теста
У продавца есть записи, показывающие, что средний покупатель тратит в ее магазине в среднем 80 долларов, но в последнее время ей кажется, что эта сумма увеличилась. Она собирает случайную выборку из n = 30 покупателей и обнаруживает, что средняя сумма, потраченная в магазине, составила $85,4, а стандартное отклонение выборки - $12,4. Достаточно ли у нее доказательств, чтобы утверждать, что средняя сумма, потраченная в ее магазине, значительно увеличилась, при уровне значимости .05?
Решение:
Была предоставлена следующая информация:
| Hypothesized Population Mean \((\mu)\) = | \(80\) |
| Sample Standard Deviation \((s)\) = | \(12.4\) |
| Sample Size \((n)\) = | \(30\) |
| Sample Mean \((\bar X)\) = | \(85.4\) |
| Significance Level \((\alpha)\) = | \(0.05\) |
(1) Нулевая и альтернативная гипотезы
Необходимо проверить следующие нулевые и альтернативные гипотезы:
\[ \begin{array}{ccl} H_0: \mu & = & 80 \\\\ \\\\ H_a: \mu & > & 80 \end{array}\]Это соответствует тесту с правым хвостом, для которого будет использован t-тест для одного среднего с неизвестным стандартным отклонением популяции с использованием стандартного отклонения выборки.
(2) Область Отторжения
Исходя из предоставленной информации, уровень значимости составляет \(\alpha = 0.05\), а критическое значение для теста с правым хвостом - \(t_c = 1.699\).
Область отклонения для этого теста с правым хвостом составляет \(R = \{t: t > 1.699\}\)
(3) Статистика Тестов
T-статистика вычисляется следующим образом:
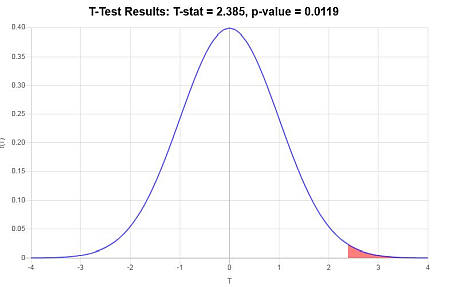
\[ \begin{array}{ccl} t & = & \displaystyle \frac{\bar X - \mu_0}{s/\sqrt{n}} \\\\ \\\\ & = & \displaystyle \frac{ 85.4 - 80}{ 12.4/\sqrt{ 30}} \\\\ \\\\ & = & 2.385 \end{array}\](4) Решение о нулевой гипотезе
Поскольку наблюдается, что \(t = 2.385 > t_c = 1.699\), то делается вывод, что нулевая гипотеза отвергается.
Используя подход P-value: P-значение равно \(p = 0.0119\), и поскольку \(p = 0.0119 < 0.05\), делается вывод, что нулевая гипотеза отвергается.
(5) Вывод
Делается вывод, что нулевая гипотеза Ho отвергается. Поэтому нет достаточных доказательств, чтобы утверждать, что среднее значение популяции \(\mu\) больше 80 при уровне значимости \(\alpha = 0.05\).
Доверительный Интервал
95% доверительный интервал составляет \(80.77 < \mu < 90.03\).
Графически