दो नमूना जेड-परीक्षण कैलकुलेटर
सराय: टी-टेस्ट के परिणामों को प्राप्त करने के लिए इस दो-नमूना जेड-टेस्ट कैलकुलेटर का उपयोग करें जब दो नमूने प्रदान किए जाते हैं, साथ ही इसी जनसंख्या मानक विचलन के साथ।कृपया नीचे आवश्यक जानकारी प्रदान करें
दो मतलब जेड-टेस्ट कैलकुलेटर
यह कैलकुलेटर सभी चरणों को दिखाते हुए, दो साधनों के लिए एक जेड-टेस्ट चलाने की अनुमति देता है।जेड-टेस्ट एक के समान है t- rayraugun , लेकिन एक स्पष्ट अंतर के साथ कि एक के मामले के लिए z- rauraugun हमें इसी जनसंख्या मानक विचलन को जानना होगा।
इस परीक्षण के लिए आपको दो नमूने प्रदान करने की आवश्यकता है, साथ ही प्रत्येक समूह के लिए संबंधित जनसंख्या मानक विचलन।आप सोच रहे होंगे, अगर मेरे पास उन जनसंख्या मानक विचलन नहीं हैं: तो क्या होता है: उत्तर सरल है: तो आप दो साधनों के लिए जेड-टेस्ट नहीं चला सकते।
एक बार जब आप सभी आवश्यक डेटा प्रदान कर लेते हैं, तो आपको बस "गणना" पर क्लिक करना होगा, और प्रक्रिया के सभी चरण आपको दिखाए जाएंगे।
एक दो-नमूना जेड-परीक्षण क्या है?
एक दो-नमूना जेड-परीक्षण एक प्रकार का जेड-परीक्षण है जो दो समूहों के साधनों की तुलना करता है।आप या तो नमूना डेटा प्रदान कर सकते हैं (जनसंख्या मानक विचलन के साथ), या आप एक चला सकते हैं संकth-kana के kanauta दो के लिए लिए जेड-टेस-टेस-टेस-टेस-टेस-टेस , जिसके लिए आपको नमूना डेटा के बदले में नमूना साधन प्रदान करने की आवश्यकता है।
आप जिन दो प्रक्रियाओं को चलाएंगे, उनमें से कौन सी प्रक्रियाएँ, नमूना डेटा के लिए Z- परीक्षण या संक्षेपित डेटा के लिए काफी हद तक इस बात पर निर्भर करेगी कि आपके पास क्या जानकारी उपलब्ध है।
दो के लिए जेड-टेस्ट फॉर्मूला
इस परीक्षण में उपयोग किए गए सूत्र के लिए एक सरल अभिव्यक्ति है।जेड-टेस्ट फॉर्मूला है
\[z = \displaystyle{\frac{\bar X_1 - \bar X_2}{\sqrt{\displaystyle{\frac{\sigma_1^2}{n_1}} + \displaystyle{\frac{\sigma_2^2}{n_2}} }}} \]इस मामले में लाभ यह है कि हमें स्वतंत्रता की डिग्री से निपटने की आवश्यकता नहीं है, जैसे कि मामले में अय्याहस के टी टी-टेस-टेस , और सामान्य रूप से टी-परीक्षणों के साथ।
इस कैलकुलेटर पर 2 सैंपल जेड-टेस्ट कैसे करें?
- Letsunt 1: उन नमूनों को पहचानें जिन्हें आप तुलना करना चाहते हैं।आमतौर पर, आप यह सुनिश्चित करने के लिए कुछ वर्णनात्मक सांख्यिकी विश्लेषण करना चाहेंगे कि नमूने यथोचित घंटी के आकार के हैं
- Their दो दो: आपको जनसंख्या मानक विचलन \(\sigma_1\)और \(\sigma_2\)की पहचान करने की आवश्यकता है।यदि आपके पास नहीं है, तो आप एक Z- परीक्षण नहीं कर सकते
- Theirण 3: नमूनों से, आपको नमूना खोजने की आवश्यकता है \(\bar X_1\)और \(\bar X_2\)
- च ४: ४: अब, आप अपनी जानकारी को फॉर्मूला \(z = \displaystyle{\frac{\bar X_1 - \bar X_2}{\sqrt{\displaystyle{\frac{\sigma_1^2}{n_1}} + \displaystyle{\frac{\sigma_2^2}{n_2}} }}}\)में प्लग करते हैं
- च ५: ५: Once you have the z-statistic, which you call, \(z_{obs}\) you need to compute the p-value
- च viry: 6: बाएं-पूंछ वाले परीक्षणों के लिए आप \(p = \Pr(Z < z_{obs})\)की गणना करते हैं।दाएं-पूंछ वाले परीक्षणों के लिए आप \(p = \Pr(Z > z_{obs})\)की गणना करते हैं और दो-पूंछ वाले परीक्षणों के लिए आप \(p = \Pr(|Z| > z_{obs})\)की गणना करते हैं
- Their च 7: एक बार जब आपके पास पी-वैल्यू होता है, तो आप महत्व स्तर \(\alpha\)के चुने हुए मूल्य के आधार पर एक निष्कर्ष निकालते हैं: यदि \(p < \alpha\), तो आप अशक्त परिकल्पना को अस्वीकार करते हैं, और अन्यथा, आपके पास अशक्त को अस्वीकार करने के लिए पर्याप्त सबूत नहीं हैंपरिकल्पना
एक महत्वपूर्ण बिंदु: यदि आप अशक्त परिकल्पना हो को अस्वीकार नहीं करते हैं, तो इसका मतलब यह नहीं है कि आप अशक्त परिकल्पना को स्वीकार करते हैं, इसका मतलब है कि आपको इसे अस्वीकार करने के लिए पर्याप्त सबूत नहीं मिल सकते हैं।
यह दो अनुपातों के लिए जेड-टेस्ट के लिए अलग कैसे है?
इस अर्थ में समान हैं कि वे दोनों जेड-परीक्षण हैं, जो उपयोग करते हैं तंग सभी संबंधित संभावनाओं को निर्धारित करने के लिए।
अंतर यह है कि वे अलग-अलग चीजों को माप रहे हैं: दो के लिए जेड-टेस्ट दो समूहों के साधनों की तुलना करते हैं, जहां इन चर को अंतराल या अनुपात स्तर पर मापा जाता है, जबकि दो अनुपातों के लिए जेड-परीक्षण एक के अनुपात की तुलना करेगाडेटा के साथ जुड़ी कुछ विशेषता।
एक्सेल में एक दो नमूना जेड-टेस्ट कैसे करें?
एक्सेल के आंतरिक कार्य हैं जो आपको जेड-टेस्ट और कई अन्य प्रक्रियाओं को चलाने की अनुमति देते हैं, लेकिन यह आपको इस कैलकुलेटर की तरह प्रक्रिया के सभी चरणों को नहीं दिखाता है।
अंत में, आप एक्सेल या किसी अन्य कैलकुलेटर से एक संख्यात्मक उत्तर प्राप्त करने में सक्षम हो सकते हैं, लेकिन आपके पास इस बात पर कदम नहीं होंगे कि आप वास्तव में एक नियमित कैलकुलेटर पर जेड-टेस्ट कैसे पाते हैं।

एक दो का एक उदाहरण जेड-टेस्ट का मतलब है
एक प्रशिक्षक शिक्षण की एक विधि का परीक्षण कर रहा है, और उसे 10 छात्रों का एक नमूना मिलता है, जो एक विधि से गुजरता है, और 11 छात्रों का एक और नमूना दूसरी विधि से गुजरता है।उन विधियों का उपयोग करके शिक्षण के बाद प्राप्त ग्रेड हैं:
समूह 1: 89, 78, 90, 100, 90, 92, 90, 80, 89, 93
समूह 2: 91, 89, 91, 95, 92, 93, 91, 87, 90, 94, 90
इसके अलावा, वह जानती है कि पहली विधि के लिए स्कोर का जनसंख्या मानक विचलन 3.4 है, जबकि दूसरे के लिए 4.1 है।क्या प्रशिक्षक यह निष्कर्ष निकाल सकता है कि तरीकों के बीच एक महत्वपूर्ण अंतर है?.05 के महत्व स्तर का उपयोग करें
समाधान:
निम्नलिखित सूचना नमूना जानकारी प्रदान की गई है:
| नमूना 1 | नमूना 2 |
| 89 | 91 |
| 78 | 89 |
| 90 | 91 |
| 100 | 95 |
| 90 | 92 |
| 92 | 93 |
| 90 | 91 |
| 80 | 87 |
| 89 | 90 |
| 93 | 94 |
| 90 |
दो-स्वतंत्र नमूना Z- परीक्षण का संचालन करने के लिए, हमें नमूनों के वर्णनात्मक आंकड़ों की गणना करने की आवश्यकता है:
| नमूना 1 | नमूना 2 | |
| 89 | 91 | |
| 78 | 89 | |
| 90 | 91 | |
| 100 | 95 | |
| 90 | 92 | |
| 92 | 93 | |
| 90 | 91 | |
| 80 | 87 | |
| 89 | 90 | |
| 93 | 94 | |
| 90 | ||
| औसत | 89.1 | 91.1818 |
| एन | 10 | 11 |
संक्षेप में, Z-Statistic की गणना में निम्नलिखित वर्णनात्मक आंकड़े का उपयोग किया जाएगा:
निम्नलिखित जानकारी प्रदान की गई है:
| Sample Mean 1 \((\bar X_1)\) = | \(89.1\) |
| Population Standard Deviation 1\((\sigma_1)\) = | \(3.4\) |
| Sample Size 1\((n_1)\) = | \(10\) |
| Sample Mean 2 \((\bar X_2)\) = | \(91.1818\) |
| Population Standard Deviation 2 \((\sigma_2)\) = | \(4.1\) |
| Sample Size 2\((n_2)\) = | \(11\) |
| Significance Level \((\alpha)\) | \(0.05\) |
(१) अशकth -kir वैकलturaury
निम्नलिखित शून्य और वैकल्पिक परिकल्पनाओं का परीक्षण करने की आवश्यकता है:
\[ \begin{array}{ccl} H_0: \mu_1 & = & \mu_2 \\\\ \\\\ H_a: \mu_1 & \ne & \mu_2 \end{array}\]यह दो-पूंछ वाले परीक्षण से मेल खाता है, और दो साधनों के लिए एक जेड-परीक्षण, ज्ञात जनसंख्या मानक विचलन के साथ उपयोग किया जाएगा।
(२) क्योरहम
प्रदान की गई जानकारी के आधार पर, महत्व स्तर \(\alpha = 0.05\)है, और दो-पूंछ वाले परीक्षण के लिए महत्वपूर्ण मूल्य \(z_c = 1.96\)है।
इस दो-पूंछ वाले परीक्षण के लिए अस्वीकृति क्षेत्र \(R = \{z: |z| > 1.96\}\)है
(३) Rauraurach आँकड़े
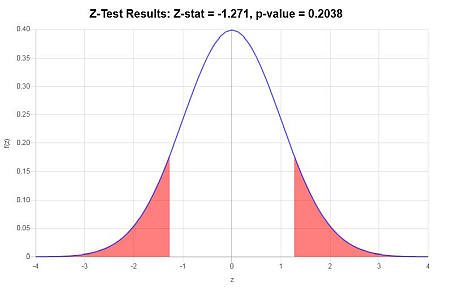
Z- स्टेटिस्टिक की गणना निम्नानुसार की जाती है:
\[ \begin{array}{ccl} z & = & \displaystyle \frac{\bar X_1 - \bar X_2}{\sqrt{ {\sigma_1^2/n_1} + {\sigma_2^2/n_2} }} \\\\ \\\\ & = & \displaystyle \frac{ 89.1 - 91.1818}{\sqrt{ {3.4^2/10} + {4.1^2/11} }} \\\\ \\\\ & = & -1.271 \end{array}\](४) अशकth -rurिकलchamataurे kair में r नि
चूंकि यह देखा गया है कि \(|z| = 1.271 \le z_c = 1.96\), यह तब निष्कर्ष निकाला जाता है अशकth -kirिकलrugramadaura अस अस kaynadaura नहीं
पी-वैल्यू दृष्टिकोण का उपयोग करना: पी-मान \(p = 0.2038\)है, और \(p = 0.2038 \ge 0.05\)के बाद से, यह निष्कर्ष निकाला गया है कि अशक्त परिकल्पना को अस्वीकार नहीं किया गया है।
(५) तिहाई
यह निष्कर्ष निकाला गया है कि अशक्त परिकल्पना हो तमाम इसलिए, यह दावा करने के लिए पर्याप्त सबूत नहीं हैं कि जनसंख्या का मतलब \(\mu_1\) \(\mu_2\)से अलग है, \(\alpha = 0.05\)महत्व स्तर पर।
विश्वास अंतराल
\(\mu_1-\mu_2\)के लिए 95% आत्मविश्वास अंतराल \(-5.293 < \mu_1 - \mu_2 < 1.129\)है।
रेखांकन
More statistical test calculators
इस कैलकुलेटर से निकटता से, आपके पास कैलकुलेटर है संकth-kana के के दो नमूनों लिए जेड जेड जेड जेड जेड जेड जेड जेड जेड जेड जेड जेड के , जो मूल रूप से एक ही प्रक्रिया का संचालन करता है, लेकिन यह पहले से ही ज्ञात वर्णनात्मक आंकड़ों का सारांश प्राप्त करता है।
के परिवार के भीतर जेड rauraumaut , we have the z-test for one mean, and the अय्याहस के जेड जेड-टेस-टेस ।
इसके अलावा, आप में रुचि हो सकती है सराय , depending on your learning setting. In more elementary settings, mixed numbers are treated as important entities, whereas in more advanced settings, mixed numbers are just presented in their fraction notation.


