एक आबादी के लिए टी-टेस्ट का मतलब है
सराय: यह कैलकुलेटर अज्ञात जनसंख्या मानक विचलन (\(\sigma\)) के साथ एक जनसंख्या माध्य (\(\sigma\)) के लिए एक टी-टेस्ट आयोजित करता है, जिसके कारण नमूना मानक विचलन (एस) का उपयोग किया जाता है।कृपया अशक्त और वैकल्पिक परिकल्पनाओं का चयन करें, परिकल्पित माध्य, महत्व स्तर, नमूना माध्य, नमूना मानक विचलन और नमूना आकार, और टी-टेस्ट के परिणाम आपके लिए प्रदर्शित किए जाएंगे: टाइप करें:
एक नमूने के लिए इस टी-टेस्ट कैलकुलेटर का उपयोग कैसे करें
के बारे में अधिक एक एक के टी टी-टेस-टेस तो आप इस सॉल्वर द्वारा प्राप्त परिणामों की बेहतर व्याख्या कर सकते हैं: एक मतलब के लिए एक टी-टेस्ट एक परिकल्पना परीक्षण है जो जनसंख्या के बारे में दावा करने का प्रयास करता है (\(\sigma\))।यह टी-टेस्ट, जेड-टेस्ट के विपरीत, जनसंख्या मानक विचलन \(\sigma\) को जानने की आवश्यकता नहीं है।

एक आबादी के लिए एक टी-टेस्ट का संचालन कैसे करें?
परीक्षण में दो पूरक परिकल्पनाएं हैं, नल और वैकल्पिक परिकल्पना।अशक्त परिकल्पना जनसंख्या के बारे में एक बयान है, बिना किसी प्रभाव की धारणा के तहत, और वैकल्पिक परिकल्पना अशक्त परिकल्पना के लिए पूरक परिकल्पना है।एक जनसंख्या के लिए एक नमूना टी-टेस्ट के मुख्य गुण हैं:
- एक माध्य के लिए एक टी-टेस्ट के लिए, टी-टेस्ट स्टेटिस्टिक के लिए उपयोग किया जाने वाला नमूना वितरण (जो इस धारणा के तहत परीक्षण सांख्यिकीय का वितरण है कि अशक्त परिकल्पना सच है) टी-डिस्ट्रीब्यूशन से मेल खाती है, एन -1 डिग्री के साथ।स्वतंत्रता की (मानक सामान्य वितरण होने के बजाय, जैसा कि एक माध्य के लिए एक जेड-परीक्षण के मामले में)
- "नो इफेक्ट" स्थिति के बारे में हमारे ज्ञान के आधार पर, टी-टेस्ट को दो-पूंछ, बाएं-पूंछ या दाएं-पूंछ किया जा सकता है
- परिकल्पना परीक्षण का मुख्य सिद्धांत यह है कि शून्य परिकल्पना को अस्वीकार कर दिया जाता है यदि प्राप्त परीक्षण सांख्यिकीय पर्याप्त रूप से इस धारणा के तहत संभावना नहीं है कि शून्य परिकल्पना सच है
- पी-मान नमूना परिणाम प्राप्त करने की संभावना है जो प्राप्त नमूना परिणामों की तुलना में चरम या अधिक चरम के रूप में है, इस धारणा के तहत कि अशक्त परिकल्पना सच है
- एक परिकल्पना परीक्षणों में दो प्रकार की त्रुटियां हैं।टाइप I त्रुटि तब होती है जब हम एक सच्ची अशक्त परिकल्पना को अस्वीकार करते हैं, और टाइप II त्रुटि तब होती है जब हम एक झूठी अशक्त परिकल्पना को अस्वीकार करने में विफल रहते हैं
एक नमूने के लिए टी-स्टेटिस्टिक की गणना कैसे करें?
तो, एक नमूना टी परीक्षण सूत्र क्या है?इस मामले में, टी-स्टेटिस्टिक के लिए इस टी-टेस्ट फॉर्मूले के लिए
\[t = \frac{\bar X - \mu_0}{s/\sqrt{n}}\]अशक्त परिकल्पना को अस्वीकार कर दिया जाता है जब टी-स्टेटिस्टिक अस्वीकृति क्षेत्र पर निहित होता है, जो कि महत्व स्तर (\(\alpha\)) द्वारा निर्धारित किया जाता है (दो-पूंछ, बाएं-पूंछ या दाएं-पूंछ) और अफ़मत्रा अफ़म \(df = n - 1\)

टी-टेस्ट के साथ क्या होता है जब मेरे पास 2 नमूने होते हैं
ध्यान दें कि यह एक नमूना टी परीक्षण कैलकुलेटर है।यदि इसके बजाय आपको दो साधनों की तुलना करने की आवश्यकता है, तो आपको एक का उपयोग करना चाहिए स स के लिए टी-टेस-टेस , बजाय।
इसी तरह से, आपके पास दो नमूने हो सकते हैं, लेकिन वे जोड़े, मिलान या दोहराए जाते हैं, जो कि उपयोग करने के लिए उपयुक्त उपकरण है युगth -yirraututh therir , जब यह मामला है।
एक नमूना टी-टेस्ट के लिए निर्णय
आप एक-नमूना टी-टेस्ट पर निर्णय कैसे लेते हैं?सबसे पहले, आपको टी-स्टेटिस्टिक को जानना होगा, जिसे हम \(t_{obs}\) कहते हैं, और फ्रीडम डीएफ की डिग्री, ताकि आप पी-वैल्यू की गणना कर सकें।
पी-मान की गणना की प्रक्रिया परिभाषित पूंछ के प्रकार पर निर्भर करेगी।दो-पूंछ वाले परीक्षण के लिए, पी-वैल्यू की गणना \(p = \Pr(|t_{df}| > |t_{obs}|)\) के रूप में की जाती है।फिर, एक बाएं-पूंछ वाले परीक्षण के लिए, पी-वैल्यू की गणना \(p = \Pr(t_{df} < t_{obs})\) के रूप में की जाती है, और एक दाएं-पूंछ वाले परीक्षण के लिए, पी-मान की गणना \(p = \Pr(t_{df} > t_{obs})\) के रूप में की जाती है।
एक नमूना टी-टेस्ट उदाहरण
एक विक्रेता के पास रिकॉर्ड दिखाते हैं कि औसत ग्राहक औसतन अपने स्टोर में $ 80 डॉलर खर्च करता है, लेकिन हाल ही में, उसे लगता है कि यह राशि बढ़ गई है।वह n = 30 ग्राहकों का एक यादृच्छिक नमूना एकत्र करती है, और वह पाती है कि स्टोर पर खर्च की गई औसत राशि $ 85.4 थी, जिसमें $ 12.4 का नमूना मानक विचलन था।क्या उसके पास यह दावा करने के लिए पर्याप्त सबूत हैं कि उसके स्टोर पर खर्च किए गए औसत में काफी वृद्धि हुई है, .05 महत्व स्तर पर?
समाधान:
निम्नलिखित जानकारी प्रदान की गई है:
| Hypothesized Population Mean \((\mu)\) = | \(80\) |
| Sample Standard Deviation \((s)\) = | \(12.4\) |
| Sample Size \((n)\) = | \(30\) |
| Sample Mean \((\bar X)\) = | \(85.4\) |
| Significance Level \((\alpha)\) = | \(0.05\) |
(१) अशकth -kir वैकलturaury
निम्नलिखित शून्य और वैकल्पिक परिकल्पनाओं का परीक्षण करने की आवश्यकता है:
\[ \begin{array}{ccl} H_0: \mu & = & 80 \\\\ \\\\ H_a: \mu & > & 80 \end{array}\]यह एक सही-पूंछ वाले परीक्षण से मेल खाता है, जिसके लिए एक माध्य के लिए एक टी-टेस्ट, अज्ञात जनसंख्या मानक विचलन के साथ, नमूना मानक विचलन का उपयोग करके उपयोग किया जाएगा।
(२) क्योरहम
प्रदान की गई जानकारी के आधार पर, महत्व का स्तर \(\alpha = 0.05\) है, और एक सही-पूंछ वाले परीक्षण के लिए महत्वपूर्ण मूल्य \(t_c = 1.699\) है।
इस दाएं-पूंछ वाले परीक्षण के लिए अस्वीकृति क्षेत्र है \(R = \{t: t > 1.699\}\)
(३) सराय
टी-स्टेटिस्टिक की गणना निम्नानुसार की जाती है:
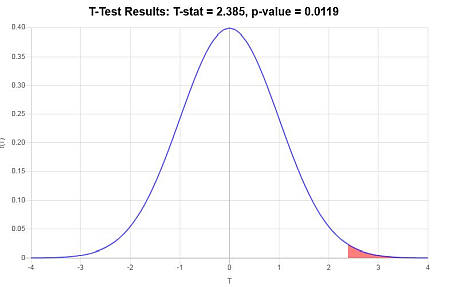
\[ \begin{array}{ccl} t & = & \displaystyle \frac{\bar X - \mu_0}{s/\sqrt{n}} \\\\ \\\\ & = & \displaystyle \frac{ 85.4 - 80}{ 12.4/\sqrt{ 30}} \\\\ \\\\ & = & 2.385 \end{array}\](४) अशकth -rurिकलchamataurे kair में r नि
चूंकि यह देखा गया है कि \(t = 2.385 > t_c = 1.699\), यह तब निष्कर्ष निकाला गया है अशकth -kirिकलrigauradaura अस अस अस अस अस
पी-वैल्यू दृष्टिकोण का उपयोग करना: पी-मान \(p = 0.0119\) है, और चूंकि \(p = 0.0119 < 0.05\), यह निष्कर्ष निकाला गया है कि अशक्त परिकल्पना को अस्वीकार कर दिया गया है।
(५) तिहाई
यह निष्कर्ष निकाला गया है कि अशक्त परिकल्पना हो तमाम दि नन्टा डाना इसलिए, यह दावा करने के लिए पर्याप्त सबूत नहीं हैं कि जनसंख्या का अर्थ है \(\mu\) \(\alpha = 0.05\) महत्व स्तर पर 80 से अधिक है।
विश्वास अंतराल
95% आत्मविश्वास अंतराल \(80.77 < \mu < 90.03\) है।
रेखांकन