在本教程中,我们将涵盖以下主题 非参数检验 .请参阅下面的相关示例问题列表,以及逐步解决方案。
问题 1: 一位医学研究人员认为,如果游泳者耳朵感染的数量可以减少 游泳者使用耳塞。选择了 10 人作为样本,记录了四个月期间耳部感染的数量。前两个月,游泳者没有使用耳塞;在接下来的两个月里,他们做到了。在第二个两个月期间开始时,对每位游泳者进行检查以确保没有感染。数据如下所示。在 \(\alpha = 0.05\),研究人员能否得出结论,使用耳塞会影响耳部感染的数量?

解决方案: 我们需要检验假设
\[\begin{aligned} & {{H}_{0}}:\text{ ear infections are the same with or without the ear plugs} \\ &{{H}_{A}}:\text{ swimmers get less ear infections with ear plugs} \\ \end{aligned}\]
我们使用签名测试。我们使用 Statdisk 得到以下输出:
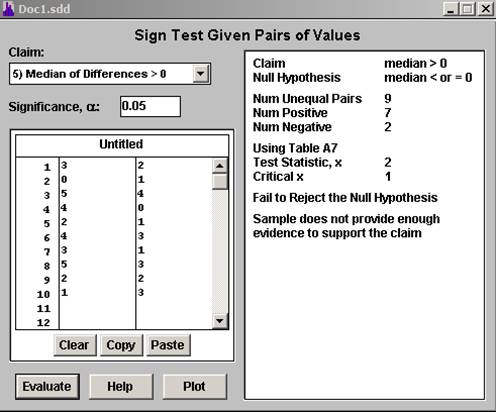
\(x\) 统计量等于 2(频率较低的符号数)。临界值为1。由于\(x\) 不小于或等于临界值,我们无法拒绝原假设。这意味着我们没有足够的证据支持游泳者使用耳塞可以减少耳部感染数量的说法。
问题2: 研究表明,自愿参与研究的人往往比非志愿者具有更高的智力。为了测试这种现象,研究人员获取了 200 名高中生的样本。学生们被描述了一项心理学研究,并询问他们是否愿意自愿参加。研究人员还获得了每个学生的智商分数,并将学生分为高,中,低智商组。以下数据是否表明智商与志愿服务之间存在显着关系?在 0.05 的显着性水平上进行检验。
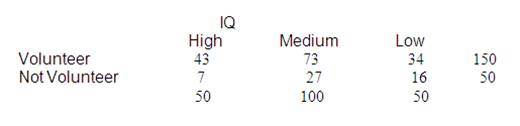
解决方案: 下表显示了相应的列联表:
|
观察到的 |
高的 |
中等的 |
低的 |
全部的 |
|
志愿者 |
43 |
73 |
34 |
150 |
|
非志愿者 |
7 |
27 |
16 |
50 |
|
全部的 |
50 |
100 |
50 |
200 |
我们有兴趣测试以下零假设和替代假设:
\[\begin{aligned}{{H}_{0}}:\,\,\, \text{Volunteer Status}\text{ and }\text {IQ}\text{ are independent} \\ {{H}_{A}}:\,\,\,\text{Volunteer Status}\text{ and }\text {IQ}\text{ are NOT independent} \\ \end{aligned}\]
从上表中,我们用期望值计算表
|
预期的 |
高的 |
中等的 |
低的 |
|
志愿者 |
37.5 |
75 |
37.5 |
|
非志愿者 |
12.5 |
25 |
12.5 |
这些预期频率的计算方式如下所示:
\[{E}_{{1},{1}}= \frac{ {R}_{1} \times {C}_{1} }{T}= \frac{{150} \times {50}}{{200}}={37.5},\,\,\,\, {E}_{{1},{2}}= \frac{ {R}_{1} \times {C}_{2} }{T}= \frac{{150} \times {100}}{{200}}={75},\,\,\,\, {E}_{{1},{3}}= \frac{ {R}_{1} \times {C}_{3} }{T}= \frac{{150} \times {50}}{{200}}={37.5}\]
\[,\,\,\,\, {E}_{{2},{1}}= \frac{ {R}_{2} \times {C}_{1} }{T}= \frac{{50} \times {50}}{{200}}={12.5},\,\,\,\, {E}_{{2},{2}}= \frac{ {R}_{2} \times {C}_{2} }{T}= \frac{{50} \times {100}}{{200}}={25},\,\,\,\, {E}_{{2},{3}}= \frac{ {R}_{2} \times {C}_{3} }{T}= \frac{{50} \times {50}}{{200}}={12.5}\]
最后,我们使用公式 \(\frac{{{\left( O-E \right)}^{2}}}{E}\) 得到
|
(fo - fe)²/fe |
高的 |
中等的 |
低的 |
|
志愿者 |
0.8067 |
0.0533 |
0.3267 |
|
非志愿者 |
2.42 |
0.16 |
0.98 |
所需的计算如下所示:
\[\frac{ {\left( {43}-{37.5} \right)}^{2} }{{37.5}} ={0.8067},\,\,\,\, \frac{ {\left( {73}-{75} \right)}^{2} }{{75}} ={0.0533},\,\,\,\, \frac{ {\left( {34}-{37.5} \right)}^{2} }{{37.5}} ={0.3267},\,\,\,\, \frac{ {\left( {7}-{12.5} \right)}^{2} }{{12.5}} ={2.42}\]
\[,\,\,\,\, \frac{ {\left( {27}-{25} \right)}^{2} }{{25}} ={0.16},\,\,\,\, \frac{ {\left( {16}-{12.5} \right)}^{2} }{{12.5}} ={0.98}\]
因此,卡方统计量的值为
\[{{\chi }^{2}}=\sum{\frac{{{\left( {{O}_{ij}}-{{E}_{ij}} \right)}^{2}}}{{{E}_{ij}}}}={0.8067} + {0.0533} + {0.3267} + {2.42} + {0.16} + {0.98} = 4.747\]
\(\alpha =0.05\) 和 \(\left( 3-1 \right)\times \left( 2-1 \right)=2\) 自由度的临界卡方值为 \(\chi _{C}^{2}= {5.991}\)。由于\({{\chi }^{2}}=\sum{\frac{{{\left( {{O}_{ij}}-{{E}_{ij}} \right)}^{2}}}{{{E}_{ij}}}}= {4.747}\) < \(\chi _{C}^{2}= {5.991}\),那么我们无法拒绝原假设,这意味着我们没有足够的证据来拒绝独立性的原假设。
问题 3: Listed below are the numbers of years that US presidents, popes since 1690 and British monarchs lived after they were inaugurated, elected, or coronated.在撰写本文时,最后一位总统是杰拉尔德福特,最后一位教皇是约翰保罗二世。时间基于计算机交互式数据分析的数据,作者是 Lunn 和 McNeil,John Wiley & Son。使用 0.05 的显着性水平来检验来自教皇和君主的 2 个长寿数据样本来自具有相同中位数的人群的说法。
总统
10 29 26 28 15 23 17 25 0 20 4 1 24 16 12 4 10 17 16 0 7 24 12 4
18 21 11 2 9 36 12 28 3 16 9 25 23 32
教皇
2 9 21 3 6 10 18 11 6 25 23 6 2 15 32 25 11 8 17 19 5 15 0 26
君主 17 6 13 12 13 33 59 10 7 63 9 25 36 15
解决方案: 我们需要使用 Wilcoxon 检验来评估 2 个样本来自具有相同中位数的总体的说法。得到以下结果:
|
Wilcoxon - 曼/惠特尼检验 |
||||
|
n |
等级总和 |
|||
|
24 |
416 |
教皇 |
||
|
14 |
325 |
君主 |
||
|
38 |
741 |
全部的 |
||
|
468.00 |
期望值 |
|||
|
33.00 |
标准差 |
|||
|
-1.56 |
z, 修正平局 |
|||
|
.1186 |
p 值(双尾) |
|||
|
不。 |
标签 |
数据 |
秩 |
|
|
1 |
教皇 |
2 |
2.5 |
|
|
2 |
教皇 |
9 |
12.5 |
|
|
3 |
教皇 |
21 |
28 |
|
|
4 |
教皇 |
3 |
4 |
|
|
5 |
教皇 |
6 |
7.5 |
|
|
6 |
教皇 |
10 |
14.5 |
|
|
7 |
教皇 |
18 |
26 |
|
|
8 |
教皇 |
11 |
16.5 |
|
|
9 |
教皇 |
6 |
7.5 |
|
|
10 |
教皇 |
25 |
31 |
|
|
11 |
教皇 |
23 |
29 |
|
|
12 |
教皇 |
6 |
7.5 |
|
|
13 |
教皇 |
2 |
2.5 |
|
|
14 |
教皇 |
15 |
22 |
|
|
15 |
教皇 |
32 |
34 |
|
|
16 |
教皇 |
25 |
31 |
|
|
17 |
教皇 |
11 |
16.5 |
|
|
18 |
教皇 |
8 |
11 |
|
|
19 |
教皇 |
17 |
24.5 |
|
|
20 |
教皇 |
19 |
27 |
|
|
21 |
教皇 |
5 |
5 |
|
|
22 |
教皇 |
15 |
22 |
|
|
23 |
教皇 |
0 |
1 |
|
|
24 |
教皇 |
26 |
33 |
|
|
25 |
君主 |
17 |
24.5 |
|
|
26 |
君主 |
6 |
7.5 |
|
|
27 |
君主 |
13 |
19.5 |
|
|
28 |
君主 |
12 |
18 |
|
|
29 |
君主 |
13 |
19.5 |
|
|
30 |
君主 |
33 |
35 |
|
|
31 |
君主 |
59 |
37 |
|
|
32 |
君主 |
10 |
14.5 |
|
|
33 |
君主 |
7 |
10 |
|
|
34 |
君主 |
63 |
38 |
|
|
35 |
君主 |
9 |
12.5 |
|
|
36 |
君主 |
25 |
31 |
|
|
37 |
君主 |
36 |
36 |
|
|
38 |
君主 |
15 |
22 |
|
由于我们正在比较两个独立的群体(教皇和君主),我们可以使用 Wilcoxon 秩和检验。
这 零假设 测试是
H0:两个样本来自具有相同中位数的总体。
这 替代假设 是
H1:两个样本来自中位数不同的总体。
显着性水平 = 0.05
测试统计: 汇集样本结果的观测值按从小到大排列。得到排名后,对样本进行分离,计算每个样本的排名总和。
这 检验统计量 使用的是
\[Z=\frac{{{T}_{A}}-\frac{{{n}_{2}}\left( {{n}_{1}}+{{n}_{2}}+1 \right)}{2}}{\sqrt{\frac{{{n}_{1}}{{n}_{2}}\left( {{n}_{1}}+{{n}_{2}}+1 \right)}{12}}}\]
,
其中 T 一种 是较小样本的秩和。这里 n 1 = 24, n 2 = 14, 吨 一种 = 416。
Therefore,\[Z=\frac{416-\frac{24\left( 14+24+1 \right)}{2}}{\sqrt{\frac{14*24\left( 14+24+1 \right)}{12}}}=-1.57\]
拒绝标准: 如果检验统计量的绝对值大于 0.05 显着性水平的临界值,则拒绝原假设。
下临界值 = -1.96
上临界值 = 1.96
结论: 无法拒绝原假设,因为检验统计量的绝对值小于临界值。该样本没有提供足够的证据来拒绝两个样本来自具有相同中位数的总体的说法。
如果您有任何建议,或者如果您想报告一个损坏的求解器/计算器,请不要犹豫 联系我们 .